Starting to understand how Flux reads your prompts
A couple of weeks ago, I started down the rabbit hole of how to train LoRAs. As someone who build a number of likeness embeddings and LoRAs in Stable Diffusion, I was mostly focused on the technical side of things.
Once I started playing around with Flux, it became quickly apparent that the prompt and captioning methods are far more complex and weird than at first blush. Inspired by “Flux is smarter than you…" I began a very confusing journey into testing and searching for how the hell Flux actually works with text input.
Disclaimer: This is neither a definitive technical document; nor is it a complete and accurate mapping of the Flux backend. These are my own notes for people who aren't ML architects, but are interested in understanding how Flux is different than SD. I’ve spoken with several more technically inclined users, looking through documentation and community implementations, and this is my high-level summarization.
While I hope I’m getting things right here, ultimately only Black Forest Labs really knows the full algorithm. My intent is to make the currently available documentation more visible, and perhaps inspire someone with a better understanding of the architecture to dive deeper and confirm/correct what I put forward here!
I have a lot of insights specific to how this understanding impacts LoRA generation. I’ve been running tests and surveying community use with Flux likeness LoRAs this last week. Hope to have that more focused write up posted soon!
TLDR for those non-technical users looking for workable advice.
Compared to the models we’re used to, Flux is very complex in how it parses language. In addition to the “tell it what to generate” input we saw in earlier diffusion models, it uses some LLM-like module to guide the text-to-image process.
We’ve historically met diffusion models halfway. Flux reaches out and takes more of that work from the user, baking in solutions that the community had addressed with “prompt hacking”, controlnets, model scheduling, etc.
This means more abstraction, more complexity, and less easily understood “I say something and get this image” behavior.
Solutions you see that may work in one scenario may not work in others. Short prompts may work better with LoRAs trained one way, but longer ‘fight the biases’ prompting may be needed in other cases.
TLDR TLDR: Flux is stupid complex. It’s going to work better with less effort for ‘vanilla’ generations, but we’re going to need to account for a ton more variables to modify and fine tune it.
Some background on text and tokenization
I’d like to introduce you to CLIP.
CLIP is a little module you probably have heard of. CLIP takes text, breaks words it knows into tokens, then finds reference images to make a picture.

CLIP is a smart little thing, and while it’s been improved and fine tuned, the core CLIP model is what drives 99% of text-to-image generation today. Maybe the model doesn’t use CLIP exactly, but almost everything is either CLIP, a fork of CLIP or a rebuild of CLIP.
The thing is, CLIP is very basic and kind of dumb. You can trick it by turning it off and on mid-process. You can guide it by giving it different references and tasks. You can fork it or schedule it to make it improve output… but in the end, it’s just a little bot that takes text, finds image references, and feeds it to the image generator.
Meet T5
T5 is not a new tool. It’s actually a sub-process from the larger “granddaddy of all modern AI”: BERT.
BERT tried to do a ton of stuff, and mostly worked. BERT’s biggest contribution was inspiring dozens of other models. People pulled parts of BERT off like Legos, making things like GPTs and deep learning algorithms.
T5 takes a snippet of text, and runs it through Natural Language Processing (NLP). It’s not the first or the last NLP method, but boy is it efficient and good at its job.
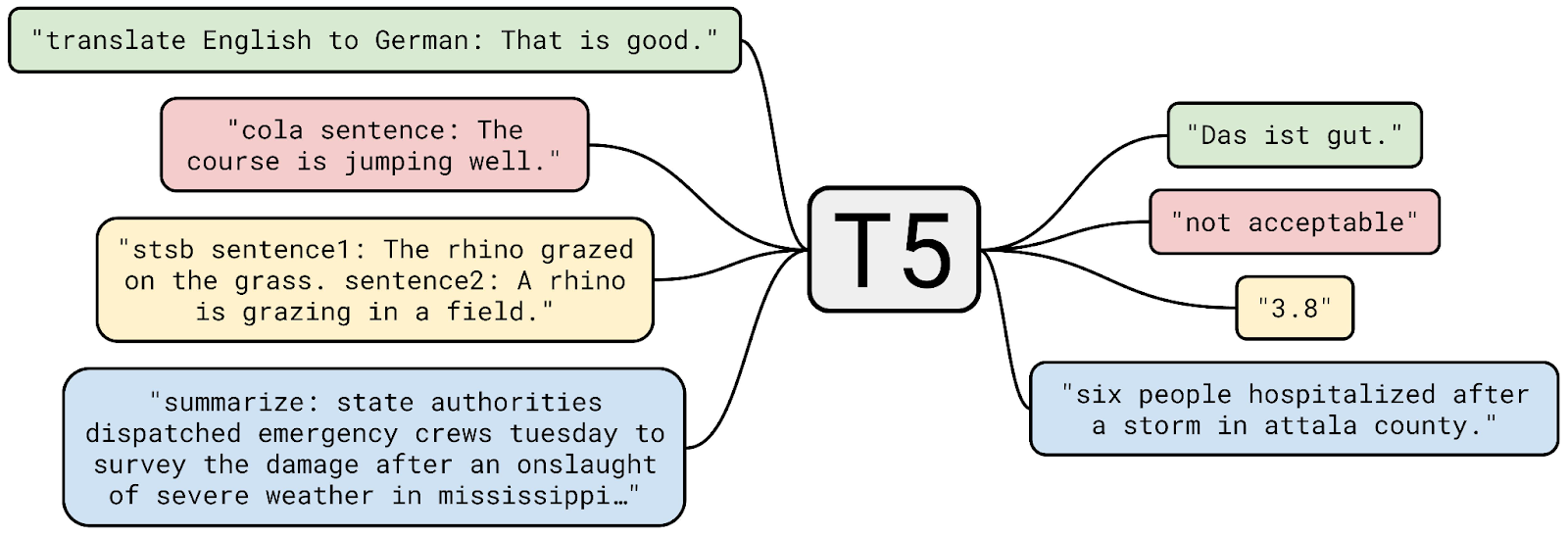
T5, like CLIP is one of those little modules that drives a million other tools. It’s been reused, hacked, fine tuned thousands and thousands of times. If you have some text, and need to have a machine understand it for an LLM? T5 is likely your go to.
FLUX is confusing

Here’s the high level: Flux takes your prompt or caption, and hands it to both T5 and CLIP. It then uses T5 to guide the process of CLIP and a bunch of other things.
The detailed version is somewhere between confusing and a mystery.
This is the most complete version of the Flux model flow. Note that it starts at the very bottom with user prompt, hands it off into CLIP and T5, then does a shitton of complex and overlapping things with those two tools.
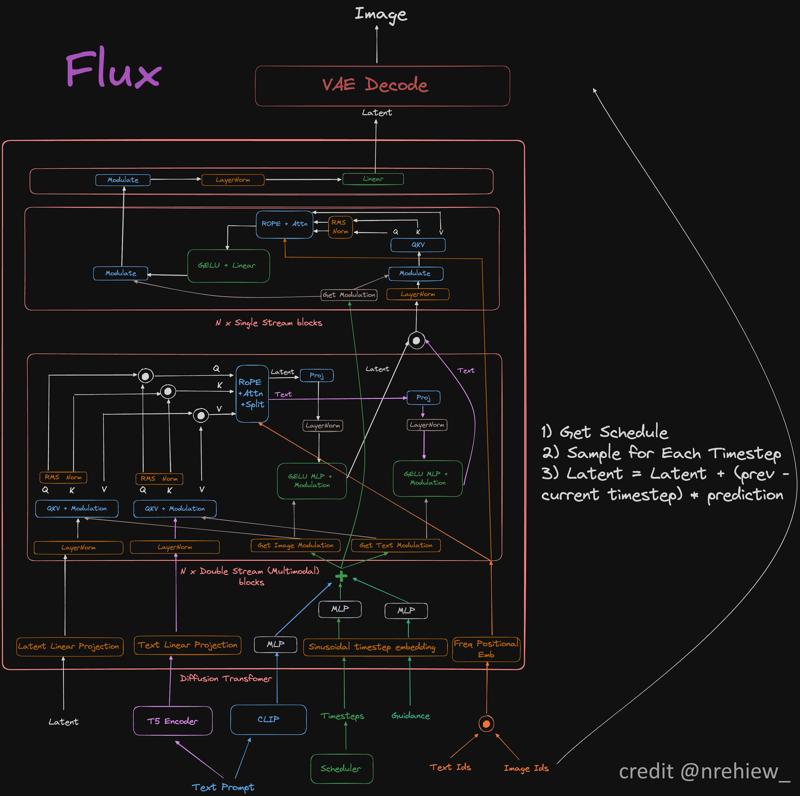
This isn’t even a complete snapshot. There’s still a lot of handwaving and “something happens here” in this flowchart. The best I can understand in terms I can explain easily:
- In Stable Diffusion, CLIP gets a work-order for an image and tries to make something that fits the request.
- In Flux, same thing, but now T5 also sits over CLIP’s shoulder during generation, giving it feedback and instructions.
Being very reductive:

CLIP is a talented little artist who gets commissions. It can speak some English, but mostly just sees words it knows and tries to incorporate those into the art it makes.

T5 speaks both CLIP’s language and English, but it can’t draw anything. So it acts as a translator and rewords things for CLIP, while also being smart about what it says when, so CLIP doesn’t get overwhelmed.
Ok, what the hell does this mean for me?
Honestly? I have no idea.
I was hoping to have some good hacks to share, or even a solid understanding of the pipeline. At this point, I just have confirmation that T5 is active and guiding throughout the process (some people have said it only happens at the start, but that doesn’t seem to be the case).
What it does mean, is that nothing you put into Flux gets directly translated to the image generation. T5 is a clever little bot, it knows associated words and language.
There’s not a one-size fits all for Flux text inputs.
- Give it too many words, and it summarizes. Your 5000 word prompts are being boiled down to maybe 100 tokens.
- Give it too few words, and it fills in the blanks. Your three word prompts (“Girl at the beach”) get filled in with other associated things (“Add in sand, a blue sky…”).
This is me scraping together a bunch disparate discussion, some of which is speculation. So far this is the only source I've found walking thought the full process...
Even then, end to end compression is still incomplete. I'm hoping others can confirm or correct. I can confirm CLIP and T5 are both considered critical to the pipeline based on documentation. It's a bit black-boxed still, but with the official GitHub code and community work will likely map it all out in the coming months.
One thing that also seems to be debated: is T5 just early process, or ongoing throughout? I'm seeing more evidence to the latter, but the specifics are still fuzzy. The community projects attempting "dual prompting" seems to point to T5 → CLIP not just being a single transformation, but rather a running collaboration.
The flowchart, while still just an early best effort, is the most complete document I've found of Flux's backend. Me being a script kiddie, I'm using that as a learning guide, walking backwards through the code base + community research.
Big shout out to Raphael Walker and nrehiew_ for their insights. (The big metaphor I use here comes from Raphael very patiently trying to break this down to me via email. Hope I did this justice!)
Also, as I was writing this up TheLatentExplorer published their attempt to fully document the architecture. Haven’t had a chance to look yet, but I suspect it’s going to be exactly what the community needs to make this write up completely outdated and redundant (in the best way possible 😊)
Thank you so much to the author for a great article!
- Link to article - https://civitai.com/articles/7309/starting-to-understand-how-flux-reads-your-prompts